🧬 Core Technology Architecture
Revolutionary innovations that make Gemma 3N the most advanced mobile AI model
🏆 Performance Leadership
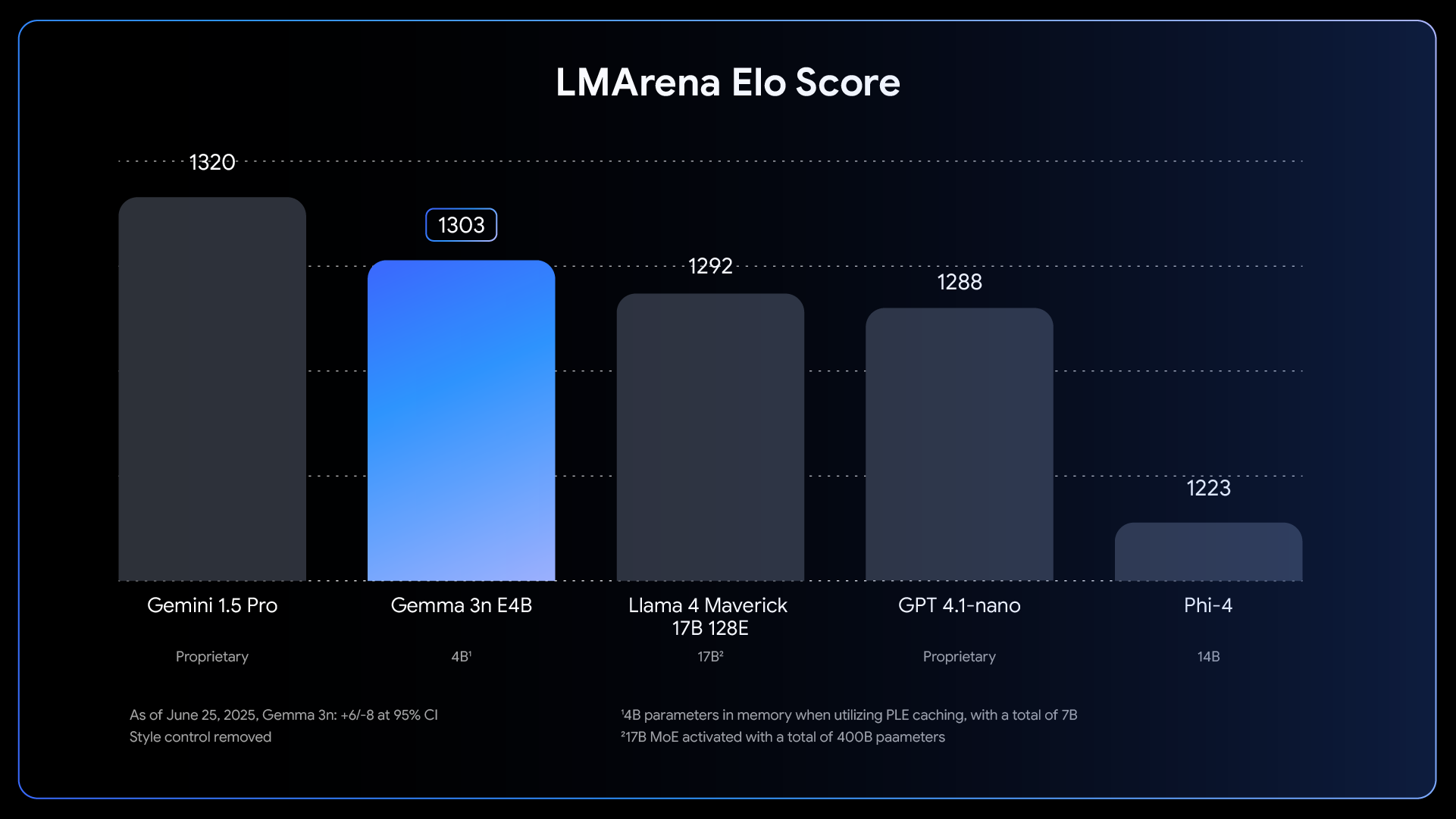
Gemma 3N E4B scores 1303 on LMArena, ranking first among 10B+ parameter models and competing with much larger proprietary models like Gemini 1.5 Pro and GPT-4.1-nano.
🔧 MatFormer: Matryoshka Transformer

🪆 Russian Doll Architecture
- Nested Model Structure: One model contains multiple sub-models with different complexities
- Flexible Depth: E2B (6 blocks) and E4B (7 blocks) with adaptive FFN multipliers
- Dynamic Switching: Future support for elastic inference with runtime model selection
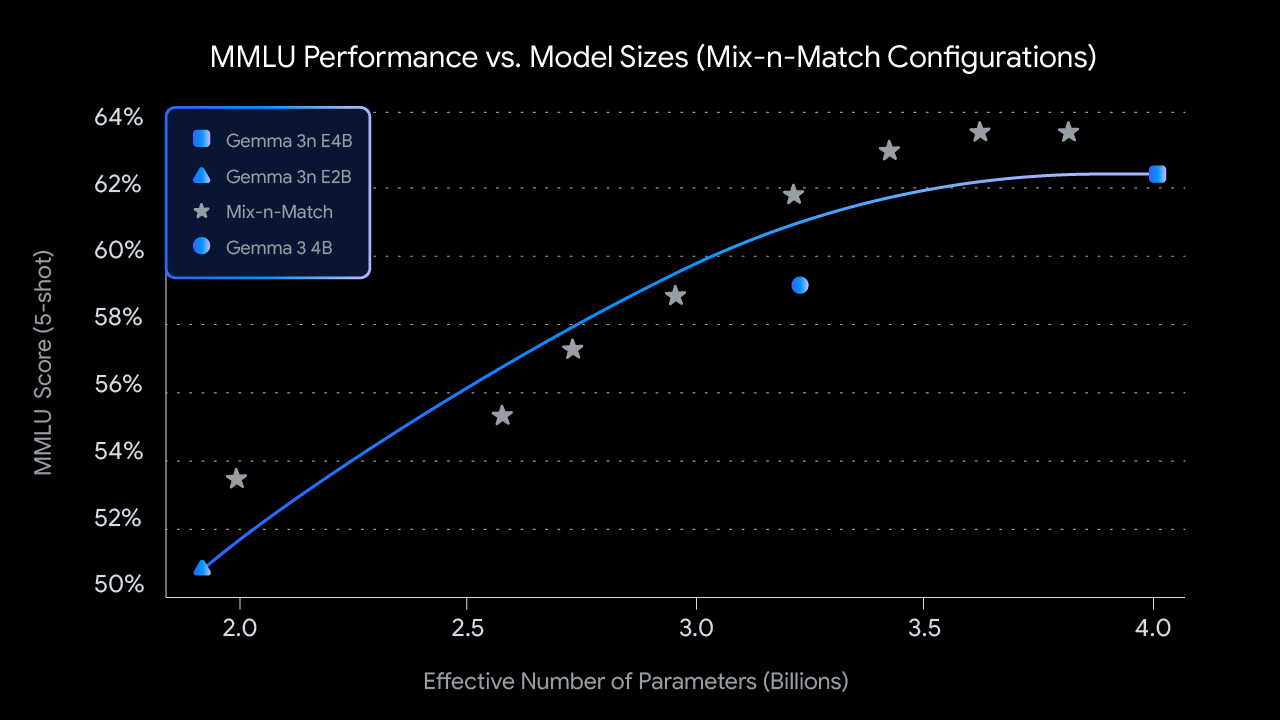
🎛️ Mix-n-Match Performance Optimization
📊 Scalable Performance
- Custom Configuration: Adjust layers and parameters for specific hardware
- Performance Range: MMLU scores from 50% to 62% across different configurations
- Efficiency Sweet Spot: Optimal performance/parameter ratio at 2-4B effective parameters
💾 PLE: Per-Layer Embeddings

🧠 Memory Revolution
- Dramatic Memory Reduction: From 5.44B to 1.91B parameters loaded (65% reduction)
- Smart Caching: Only core Transformer weights in GPU memory, embeddings cached to fast storage
- Optional Loading: Audio and vision parameters loaded only when needed
🚀 Innovation Summary
1303
LMArena Score
Best in class 10B+
65%
Memory Reduction
With PLE caching
7+6
Flexible Blocks
MatFormer architecture